Time:2023-09-08 Click:233
ChatGPT 带动了全球大模型热潮,互联网公司陷入“百模大战”,甚至出现了“内卷”:各家公司发布的大模型一个比一个大,参数规模成了宣传噱头,几乎都在百亿、千亿甚至万亿以上。
然而,也有人提出这种现状并非可持续的发展方式。OpenAI 创始人 Sam Altman 称 GPT-4 的开发成本突破了一亿美元,Analytics India Magazine 发布的报告显示, OpenAI 每天将花费约 70 万美元来运行其人工智能服务 ChatGPT。同时,LLM 也会引起人们对电力消耗的担忧,谷歌报告称,培训 PaLM 在大约两个月内耗费了大约 3.4 千瓦时,相当于大约 300 个美国家庭每年的能源消耗量。
因此,随着模型规模的不断增大,HuggingFace 首席布道师 Julien Simon 却说“Smaller is better”。事实上,在参数规模达到一定程度后,再增加参数往往对模型效果的提升并不明显,从实用性和经济性来考虑,模型“瘦身”是一项必然的选择,因为相对于庞大的参数规模所带来的递减边际效益,巨大的资源消耗成本往往不值得。而且,大模型因规模太大将在应用上产生诸多问题,比如无法部署在边缘设备上,只能以云的形式向用户提供服务,然而很多时候,我们需要将模型部署在边缘节点,以提供用户个性化服务。
如果要继续改进 AI 模型,开发者将需要解决如何以更少的资源实现更高性能的问题。无论是在学术界还是在工业界,大模型压缩一直是一个热门领域,目前也有很多技术在做。本文简单介绍四种常见的模型压缩手段:量化、剪枝、参数共享和知识蒸馏,帮助大家对模型压缩方法有一个直观的了解。
如果我们把模型比作一个“水桶”,把数据比作“苹果”,把数据中含有的信息比作“苹果汁”,那么训练大模型的过程,就可以理解为用水桶装苹果汁的过程。苹果越多,苹果汁就越多,我们也需要更大的水桶来盛放苹果汁。大模型的出现就犹如我们造出了更大的水桶,从而有更大的能力装足够的苹果汁。
如果苹果太多,苹果汁太多,就会导致“溢出”,也就是模型规模太小,无法学习到数据集中所有的知识,我们称这种情况为“欠拟合”,即模型无法学习到真实的数据分布;如果苹果太少,苹果汁太少,就会导致“装不满”。如果通过增加模型训练时长来“强行榨汁”装满水桶,就会导致果汁中杂质增多,从而出现模型性能下降,我们称这种情况为“过拟合”,即模型过分学习数据导致的通用性下降。因此,模型规模与数据规模的匹配是非常重要的。
以上例子虽然形象,但容易产生一种误解:一升水桶能装一升苹果汁,两升水桶就能装两升(如①)。但实际上,参数所能容纳的信息并不随参数规模线性增加,而是趋于一种“边际递减”的增长(如②③)。

换句话说,大模型所表现出的超凡能力,是因为学到了很多“细节性知识”,而且花在“细节性知识”上的参数数量庞大。当我们已经学到数据中大部分知识的时候,再继续学习更多的细节知识,就需要增设更多的参数。如果我们肯牺牲一些精度,忽略掉部分细节性信息,或者将识别细节性信息的参数进行裁剪,就可以将参数规模降低很多,而这正是学术界和工业界模型瘦身的理论基础和核心思路。
这种方法的理论基础,是在量化派中存在的一个共识:复杂的、高精度的模型在训练时是必要的,因为我们需要在优化时捕捉微小的梯度变化,然而在推理时并没有必要,因此量化可以做到只降低模型占用空间而不过于降低推理能力。
大模型规模庞大,结构复杂,内部参杂着大量作用微小甚至无用的参数和结构。如果我们能尽可能精确锁定无用之处,将其剔除,那么也能够在保证功能的同时降低模型的规模。
在大多数神经网络中,通过对网络层(卷积层或者全连接层)权重数值进行直方图统计,可以发现,训练后的权重数值分布近似正态分布或多正态分布的混合,接近于 0 的权重相对较多,这就是“权重稀疏”现象。
权重数值的绝对值大小可以看作重要性的一种度量,权重数值越大对模型输出贡献也越大,反之则不重要,删去后对模型精度的影响也比较小。
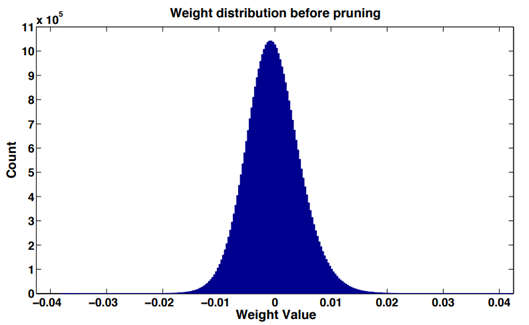
同时,在深度网络中,存在着大量难以激活的神经元。论文《Network Trimming: A Data-Driven Neuron Pruning Approach towards Efficient Deep Architectures》经过了一些简单的统计,发现无论输入什么样图像数据,CNN 中的许多神经元都具有非常低的激活。作者认为,零神经元很可能是冗余的,可以在不影响网络整体精度的情况下将其移除。我们称这种情况为“激活稀疏”。
因此,针对神经网络上述特点,我们可以针对不同的结构进行裁剪优化,从而减小模型的规模。
在技术领域,我们通常用 PCA 算法进行降维,寻找高维数组在低维的映射。如果我们寻找到模型参数矩阵的低维映射,则可实现保证性能的同时降低参数量。
目前已经有多种参数共享的方法,比如对权重进行 K-means 聚类,以及采用哈希方法随机分类,然后对同一组的权值进行处理等。
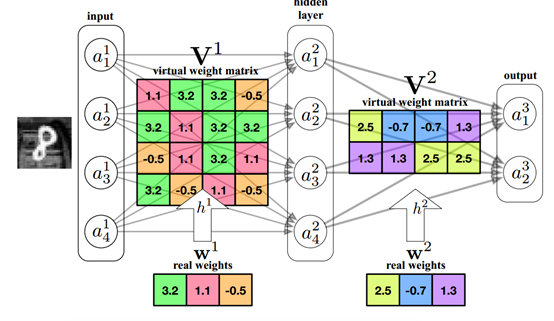
前三种方法或多或少都改变了原有模型的参数或结构,而知识蒸馏则相当于重新训练了一个规模较小的模型,因此相比其他方法来讲更能保全原有模型的功能,只是损失了部分精度。
https://zhuanlan.zhihu.com/p/102038521
https://arxiv.org/abs/1607.03250
https://arxiv.org/abs/1806.09228
https://arxiv.org/abs/1504.04788
版权声明:如需转载欢迎加小助理微信沟通,未经允许转载、洗稿、我方将保留追究法律责任的权利。
免责声明:市场有风险,投资需谨慎。请读者在考虑本文中的任何意见、观点或结论时严格遵守所在地法律法规,以上内容不构成任何投资建议。

Axie Infinity是在以太坊区块链技术上搭建的,受神奇宝贝启迪的数据宠物世界,所有人都能够根据娴熟的游戏游戏玩法和对生态体系的奉献来得到代币奖赏。为了更好地建立更强的客户体验并提升可扩展性,Axie Infinity精英团队已经搭建...

通讯技术元宇宙的一个关键原素是可以与大家相互连接。元宇宙是根据VR/AR技术完成体感互动,但VR/AR技术必须耗费很多数据信息,那麼将传输数据至云空间测算再意见反馈至设备便是一个不错的计划方案。殊不知现今的技术难题取决于完成低延时的联接,这...

专业人员早已看到了把握此项技术性的益处。服饰和品牌汽车可以推广产品,文化艺术参与者可以在这种新情景中展现,公司可以把这儿做为工作中区域的拓宽,例如西班牙埃森哲公司就与微软公司一同创立了一个“模拟校园”,让世界各国的新合作方踏入融合之途。这一...

AI检索并读取了周边一些网络服务器的边缘云存储资源,将你的聊天语音与你出世至今的视频语音历史时间数据库查询的互联网大数据开展核对,剖析鉴别出你的视频语音的主要含意;随后AI帮你在网络上订了景点的门票费,而且预订了无人车专车接送;这种买卖都是...