Time:2023-09-01 Click:210
原文来源:Filecoin Network

编者按:本文主要取材于 David Aronchick 在 2023 年巴黎 Filecoin Unleashed 大会上的演讲。David 是Expanso的首席执行官,也是协议实验室(Protocol Labs)的前数据计算负责人,该实验室负责Bacalhau项目的启动。本文仅代表原创内容创作者的独立观点,并已获得重新发布的许可。
据IDC称,截至 2025 年,全球存储的数据量将超过 175 ZB。这是一个庞大的数据量,相当于 175 万亿个 1 GB 的 U 盘。这些数据大部分在 2020 年至 2025 年之间产生,预计复合年增长率为 61% 。
如今,快速增长的数据圈出现了两大挑战:
移动数据既缓慢又昂贵。若您试图以目前的带宽下载 175 ZB 的数据,大约需要 18 亿年。
合规任务繁重。全球有数百种与数据相关的管理规定,使得跨司法管辖区的合规任务几乎不可能完成。
网络增长乏力和监管限制的综合结果是,近 68% 的机构数据处于闲置状态。正因如此,将计算资源转移至数据存储地(广义上称之为 compute-over-data ,即“数据计算”)而不是将数据转移至计算地变得尤为重要,Bacalhau 等数据计算(CoD)平台正在为此而努力。
在接下来的章节中,我们将简要介绍:
当下的机构如何处理数据。
提出基于“数据计算”的替代解决方案。
最后,假设分布式计算为何重要。
选择世界上任何地方的数据集。
遵循任何治理结构,无论是 HIPAA、GDPR 还是 FISMA。
尽可能以最低廉的价格运行。
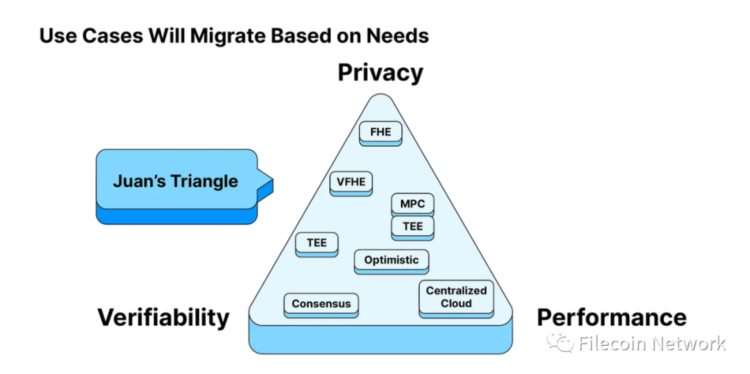
Juan Benet 解释为何不同用例(在未来)会有不同的分布式计算网络来支持时创造的。
胡安三角提出,计算网络通常需要在隐私、可验证性和性能这三者之间进行权衡,传统的“一刀切”方法很难适用于每种使用情况。相反,分布式协议的模块化特性使不同的分布式网络(或子网络)能够满足不同的用户需求——无论是隐私、可验证性还是性能。最终,我们将根据自己认为重要的因素进行优化。届时,将有许多方服务提供者(如三角形内方框所示)填补这些空白,并使分布式计算成为现实。
总而言之,数据处理是一个复杂的问题,需要开箱即用的解决方案。利用开源数据计算来替代传统的集中式系统是很好的第一步。最终,在 Filecoin 网络等分布式协议上部署计算平台,可以根据用户的个性化需求自由配置计算资源,这在大数据和人工智能时代至关重要。
请关注CoD 工作组,了解分布式计算平台的所有最新动态。欲知 Filecoin 生态的更多进展,请关注Filecoin 洞察博客,并请在Filecoin 洞察的推特、Bacalhau、Lilypad、Expanso以及COD WG上关注我们。

ŞimdidahailginçbirnoktayageleceğimBuuyarımektubundaise,konumuzunkriptoparalarvedijitalparalarolmadığı,acilenTeksasolayla...

GigaWallet、sadeceçevrimiçiveyafizikselmağazalardadeğil、aynızamandasosyalmedyaplatformlarındada埃隆·马斯克(ElonMusk)在狗狗币上的表现非常...

利率计算,以降到最低周期时间按复利计息。每每系统软件产生危害借款利率的事情(如:储蓄、贷款、赎出、贷款担保仓结算等)便会再次计算相对应财产池的借款利率,测算应付利息,与此同时将应付利息折成本费金记入相匹配贷款人的帐户(即复利计息)。在交易活...

这个问题是个好问题。让我举个例子。例如,我在银行存了100元。存款数据仅记录在银行数据库中,其他人无法获得,即中央会计。区块链是一种新的信息记录技术,它是加密和分布式。数据不存在于一个中心,而是存储在整个网络的计算机上。. 比如我给你转账1...